
By D&A Team (Gaurav Gupta)
The impact of huge amount of data on services business is seismic. Industries such as the Travel, Bank, Transportation, Hospitality, Health Insurance, Retail, and Telco has tremendous amount of data which is one of the great headaches for call centers or customer service applications which are siloed data, and for a long time, it remained that way. For example, A bank would need a different call center for credit cards than for home loans, With data virtualization spanning the data silos, everyone from a call center to a database manager can see the entire span of data stores from a single point of access without struggling to get data from different departments and then do consolidation.
Coforge understands that there are three corners for storage industry which are Fast Performance, Cheaper Price and Safe Protection. Coforge use data virtualization framework to enable the management to access and control across the enterprise in multiple databases and systems.
Data Virtualization solution will map the data from disparate sources (i.e on-premise data, or other external ones) and creates a virtualized layer which can then be seamlessly exposed to consumer applications. This approach is significantly faster since the data need not be physically moved from the source systems.
The moment data comes to the mind, people get confused with the meaning and usage of Data Integration, Data Lake and Data Virtualization while data virtualization and data lakes are not competitors nor should they be confused. A data lake which is a central storage repository that holds big data from many sources in a raw, granular format. It can store structured, semi-structured, or unstructured data, which means data can be kept in a more flexible format for future use, that source of data can be one of the source you connect in a data virtualization environment.
On the other hand, Data integration is something you do and end users look at later stage and data virtualization is the means to get then and there with low latency. Integration, as the name implies, is the process of combining data from a heterogeneous data stores of different formats to create a unified view of all that data. You use data virtualization to bridge the different data silos, then perform the joining, transforming, enriching, and cleaning of the data before integrating it into a dashboard or some other visualization methodology.
Let’s discuss Data Virtualization in detail
Data virtualization is a logical data layer that integrates all enterprise data siloed across the disparate systems, manages the unified data for centralized security and governance, and delivers it to business users in real time.
With data virtualization, you can query data across many systems without having to copy and replicate data, which reduces costs. It also can simplify your analytics and make them more up to date and accurate because you’re querying the latest data at its source. It should be noted that data virtualization is not a data store replicator. Data virtualization does not normally persist or replicate data from source systems. It only stores metadata for the virtual views and integration logic. Caching can be used to improve performance but, by and large, data virtualization is intended to be very lightweight and agile.
Data virtualization has many uses, since it is simply the process of inserting a layer of data access between disparate data sources and data consumers, such as dashboards or visualization tools. Some of the more common use cases include:
- Data Integration: This is the most likely case you will encounter, since virtually every company has data from many different data sources. That means bridging an old data source, housed in a client/server setup, with new digital systems like social media. You use connections, like Java DAO, ODBC, SOAP, or other APIs, and search your data with the data catalog.
- Big Data and Predictive Analytics: The nature of data virtualization works well here because Big Data and predictive analytics are built on heterogeneous data sources. It’s not just drawing from an Oracle database/RDBMS, Big Data comes from things like Web portal, Cellular Phone, social media, and email. So data virtualization lends itself to these highly diverse methodologies.
- Operational/end Usage: One of the great headaches for call centers or customer service applications is siloed data, and for a long time, it remained that way. A bank would need a different call center for credit cards than for home loans, for example. With data virtualization spanning the data silos, everyone from a call center to a database manager can see the entire span of data stores from a single point of access.
- Cloud Migration: Data virtualization technology can provide a secure and efficient mechanism to replace TB-size datasets from on-premise to the cloud, before spinning up space-efficient data environments needed for testing and cutover rehearsal.
How it works
Solution will empowers business users to access and manage their own data. It provides a virtual layer or view, giving users the appropriate level of control without physically moving data.
By accessing data virtually, there will not be any need to move data, replicate it or retrieve it from tables to perform analysis.
Data virtualization uses a simple three-step process to deliver a holistic view of the enterprise i.e. connect to any data source, combine any type of data and consume the data in any mode
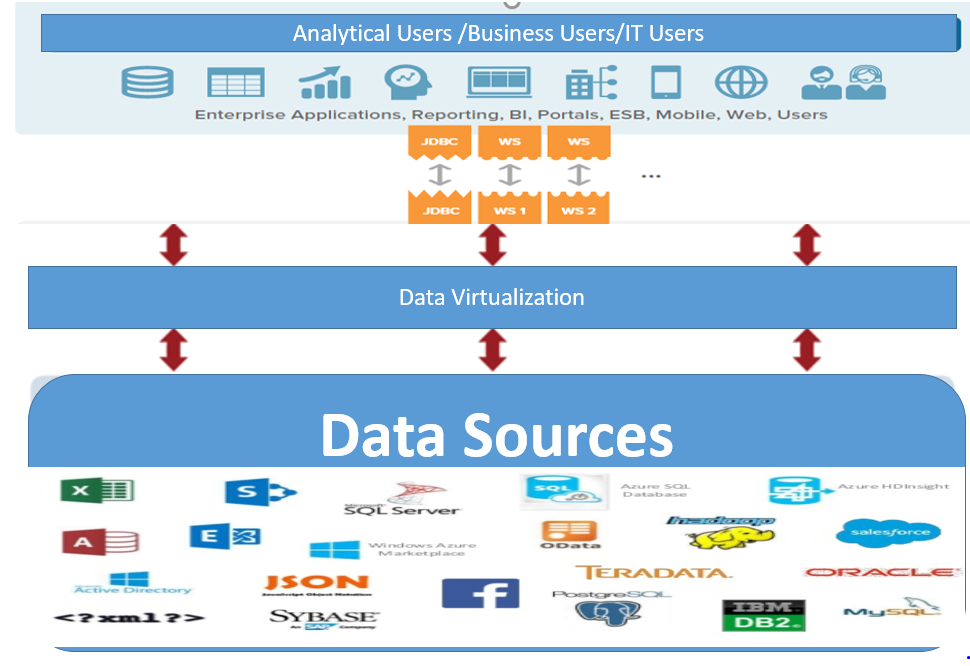
Essentially, data virtualization software is middleware that allows data stored in different types of data models to be integrated virtually. This type of platform allows authorized consumers to access an organization's entire range of data from a single point of access without knowing (or caring) whether the data resides in a glass house mainframe, on premises in a data warehouse or in a data lake in the cloud.
Because data virtualization software platforms view data sources in such an agnostic manner, they have a wide range of use cases. For example, the centralized management aspect can be used to support data governance initiatives or make it easier to test and deploy data-driven business analytics apps.
Data virtualization Software decouples the database layer that sits between the storage and application layers in the application stack. Just like a hypervisor sits between the server and the OS to create a virtual server, database virtualization software sits between the database and the OS to abstract/virtualize the data store resources.
The recommended architecture consists of minimally four layers of views:
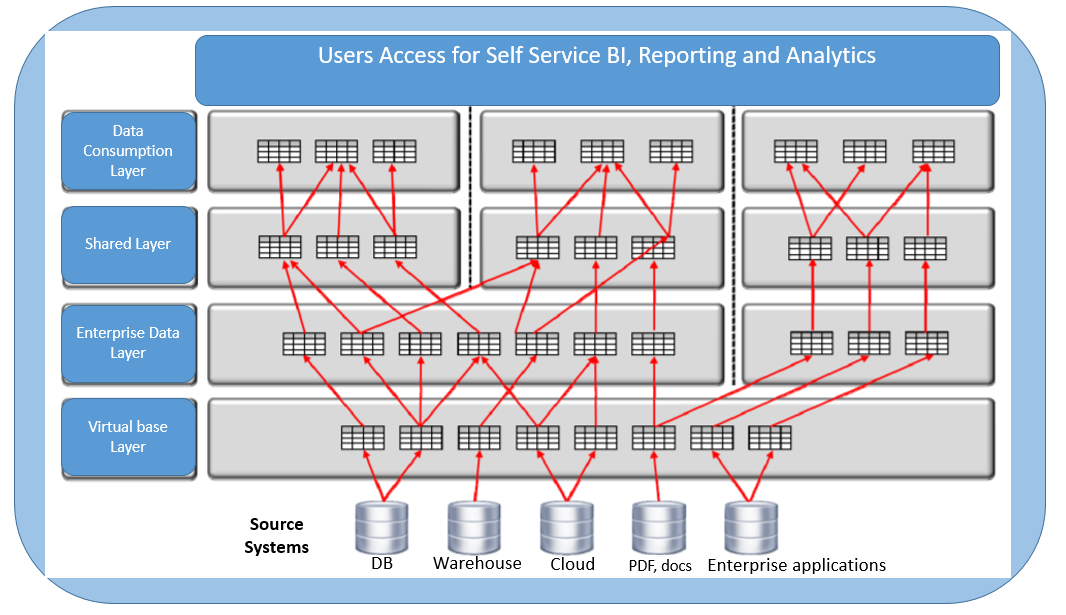
- Virtual Base Layer views give access to data stored in source systems and are partly responsible for the data quality.
- Enterprise Data Layer views present an integrated view of all the source systems’ data.
- Shared Specifications Layer views contain shared specifications to avoid duplicate and possibly inconsistent specifications in the data consumption views.
- Data Consumption Layer views simplify data access for data consumers.
What all to consider before choosing Data Virtualization tool?
There are number of products and tools available for Data Virtualization, but it is important to consider below factors before selecting the right set of Data Virtualization software:
- Applications/Data Sources. Need to see what applications/Systems that will be consuming the data and ensure the data virtualization technology has the right type of integration, connectors being available to connect to different systems/data sources as per your needs.
- Performance/Latency. Before selecting on a virtualization solution, check if it comes with symmetric multiprocessing support (SMP) or asymmetric multiprocessing support (AMP), or both combined. If the infrastructure includes multiple processors of the same type you will need SMP, while using different processors will require AMP.
- Augmented Data Preparation feature: Data preparation is good to have along with some cleansing and transformation features so that users can do the massaging of the data on its own.
- Security and compliance. Data should not be exposed AS-IS to any users since we are connecting to the data sources directly. Consider the impact of data virtualization on existing security and compliance requirements and be sure to choose a solution that addresses those concerns in terms of masking the data before releasing to the users or providing row level security sort of things to ensure right set of data is available to authorized users.
Here is a list of few Data Virtualization products with their differentiators
Actifio- Integrated rollback and recovery
Atscale- Lots of integration options with Business Intelligence tools.
DataCurrent– Places emphasis on data stored in NoSQL repositories, cloud services and application data as well as supporting business intelligence tools to connect to these data sources.
Data Virtuality- Precise data filed level collection and virtualization from data sources.
Denodo- Data catalog features that helps users to find the right data for analysis.
IBM Cloud Pak for Data- Converged solution for both data virtualization and analyze.
Red Hat JBoss Data Virtualization- Integration with Kubernetes and container based environments.
SAS Federation Server- Places great emphasis on securing data.
Stone Bond Enterprise Enabler- Company is deeply focused on data virtualization.
TIBCO Data Virtualization- Ability to create data services from virtualized data.
There are many other tools available in the market for Data Virtualization and Coforge has data experts available trained on multiple set of tools and technologies to implement data virtualization.
Key steps to implement Data Virtualization-
Coforge recommends 6 key steps for implementing data virtualization
- Roadmap : Develop a strategic roadmap and Organization should analyze and determine how the data to be consumed by creating a plan with current and future objectives (Short term and Long term) which are logically sequenced and connected to make services realized incrementally without business users and consumers to wait for long time.
- Inventory: Create a complete inventory list what is a necessary data and where source data is located and how it is managed and maintained (its accuracy, consistency, history, load frequency, data volume Data Retention etc.).
- Complete Documentation: Detailed document with data standards and specifics of the data which will feed to the Metadata since Metadata represents data about data. It enriches the data with information that makes it easier to find, use and manage. For instance, HTML tags define layout for human readers. Semantic metadata helps computers to interpret data by adding references to concepts in a knowledge graph
- Relationship among the data:There has to be logical relationships between the desired and necessary data to ensure that combinations of disparate data from different sources would make business sense once it is logically virtualized.
- Pulse of the data: Organization/users should understand how different data sets may need to be coupled/combined with external systems or constituent data for insight or foresight purposes.
- Data Protection and security: Rationalize data privacy and security requirements across the different data systems from the data being fetched to be virtualized.
How will Data Virtualization benefit the Industry
It has number of capabilities which will help the industry as well as business:-
- Cost: There is a cost saving since it is less costly to have the storage and maintenance of data since replication is not needed.
- Decoupling: Different data sources can now talk to each other with consolidated and meaningful results through data virtualization
- Govern the data: Data governance processes and policies can be easily applied to all types of data from the centralized location.
- Better productivity: Aside from the aforementioned bridging of data, virtualization also makes it easier to test and deploy different data applications since it takes lesser time in integrating the data
- It provides access to shared, secure enterprise data to speed and simplify data preparation through a kind of data-as-a-service approach.
Coforge feels that operationalizing this delicate balance using right set of technologies and implementation methodology is a primary key to success and one of the most important criteria in restoring the overall health of the storage system and provide right data to right customers on time.
Coforge’s Data and Analytics practice is one of the fastest growing practices within Coforge with over 2500 data practitioners, 100+ delivered projects, partnerships with major software vendors and over 75 data and analytics customers worldwide and has worked on multiple tools and technologies with different domains.
Coforge has deep experience across many different Data Integration, Data Virtualization, MDM tools etc and has worked with multiple clients across industries partnering with them on their Data and Analytics initiatives. We provide end-to-end Data and Analytics services from strategy and roadmap definition, Data COE setup and operationalization, Data tool selection and estimation, development and support. Coforge has frameworks, methodologies, accelerators and jumpstart solutions that can be leveraged to improve quality, reduce risk and improve time to market for client engagements.