

When we implement Scheduled Jobs in Mule (MuleSoft's Runtime Engine) to process large volumes, it is best practice to use pagination. However if pagination is not applied correctly, we will encounter challenges, which, if not resolved, might lead to revenue loss, decreased productivity and lots of rework. In this blog, we look at how we can successfully apply pagination in Scheduled Jobs and avoid problems with:
- Handling large volumes – datasets
- Memory
- Processing/CPU cycles
- Core allocation
- Scaling – multiple workers
If we implement design patterns correctly, we could avoid most of these challenges. Below, we describe one such standard pattern that you can follow to implement a Mule Scheduled Job and save significant time and effort. Moreover, you can use it as a standard template / best practice across the organisation for any such implementation.
Proposed solution
This pattern is based on the API-Led connectivity principle and can be used to integrate two systems using a Mule Scheduled Job:
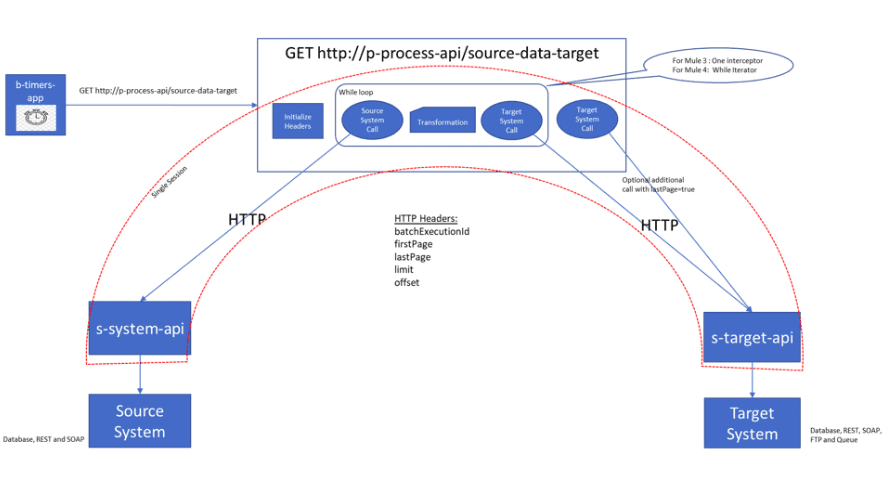
* The interaction depicted within the red-dotted area should be within the same session.
Step 1:
b-timers-app: Implement a timer app (could be a Mule app) which applies a timer and invokes the Process API in a fixed and configurable schedule.
Step 2:
p-process-api: Implement a Process API that exposes a REST GET API to be invoked by the timer app or by the operations team (ad-hoc).
The URL pattern of the GET API should be http://p-process-api/<<source-data-target>>
- <<source>> should be replaced by the actual Source System Name (E.g. Order Management System (OMS)),
- <<data>> should be replaced by the actual data (E.g. order)
- <<target>> should be replaced by the actual Target System Name (E.g. Warehouse).
The Process API should carry-out the following activities:
- Initialise Headers: It should initialise the following headers:
- batchExecutionId: String initialised by the Process API which can be passed to both Source and Target System APIs for internal logic.
- firstPage: Boolean set to true in case the first set of records are being processed and in all other cases, should be set to false.
- lastPage: Boolean set to true in case the last set of records are being processed and in all other cases, should be set to false.
- limit: Number of records that needs to be processed
- offset: offset value to specify which record to start from while retrieving data
- The next 3 steps should be called within a while loop – a customised while loop needs to be implemented in Mule 4.x.
- Source System Call: The Process API should call the System API (s-system-api) using the REST GET endpoint to fetch the records to be processed by passing the initialised headers. It should use the parameters limit and offset to read data from the source system.
- Transformation: Necessary transformations should be applied to convert the data from source system format to target system format.
- Target System Call: The Process API should call the System API (s-target-api) using the REST POST endpoint to push the processed records along with the initialised headers. It should send the parameters firstPage and lastPage along with the processed records to the target system.
- Source System Call: The Process API should call the System API (s-system-api) using the REST GET endpoint to fetch the records to be processed by passing the initialised headers. It should use the parameters limit and offset to read data from the source system.
- Target System Call (Optional): Optionally, a call may be required to the s-target-api to denote end of processing by sending lastPage=true.
- It will be required in the situation when the Source System returns same number of records as that of passed limit in the final read, and the Process API is unable to determine that it has fetched the final record.
- In the subsequent call to the Source System, the Process API won’t get back any record. In this case, the Process API has to make a call to the Target System to just to denote that it has reached end-of-processing by sending the lastPage=true parameter only (no records).
- It will be required in the situation when the Source System returns same number of records as that of passed limit in the final read, and the Process API is unable to determine that it has fetched the final record.
Step3:
s-system-api: Implement a System API should expose a GET endpoint for the Process API to fetch the records from the underlying Source System of Record.
- It should accept the filter criteria, limit and offset and respond with only those records matching the criteria.
- The s-system-api can be used when the Source System is a database or supports REST or SOAP.
Step4:
s-target-api: This System API that expose a POST endpoint for the Process API to push the processed records to the Target System.
- It should accept the headers batchExecutionId, firstPage and lastPage to implement some internal logic. E.g. it can use the headers batchExecutionId and firstPage to create a file or it can use the batchExecutionId and lastPage to move the output file from a temporary folder to the target folder.
- The s-target-api can be used when the Target System is a database or supports REST, SOAP, SFTP and Messaging.
If you would like to discuss how you can schedule jobs in Mule 4.x or have any other queries about your Anypoint Platform, then give us a call on +44 (0)203 475 7980 or email us at Salesforce@coforge.com
Other useful links:

Related reads.


About Coforge.
We are a global digital services and solutions provider, who leverage emerging technologies and deep domain expertise to deliver real-world business impact for our clients. A focus on very select industries, a detailed understanding of the underlying processes of those industries, and partnerships with leading platforms provide us with a distinct perspective. We lead with our product engineering approach and leverage Cloud, Data, Integration, and Automation technologies to transform client businesses into intelligent, high-growth enterprises. Our proprietary platforms power critical business processes across our core verticals. We are located in 23 countries with 30 delivery centers across nine countries.