
.jpeg?width=1813&height=490&upsize=true&upscale=true&name=WP%20Item%201%20(1).jpeg)
Quick Glance.
Recent progress in Natural Language Generation enables machines to create human-quality text, respond to queries, and participate in meaningful dialogue. Retrieval Augmented Generation (RAG) has become the most popular approach for embedding factual content and delivering contextually relevant responses in applications like chatbots and Q&A. RAG, while powerful, suffers from latency and reliance on external data. Cache Augmented Generation (CAG) addresses these challenges. In CAG, frequently accessed information is stored in a cache rather than retrieved on-demand, leading to performance gains. Knowledge Augmented Generation (KAG) takes it a step further by imparting domain knowledge into the generation process (within the model itself), enabling deeper reasoning and context awareness. This blog post will examine these evolutions, their payoffs, and real-world implementations.
Architectural Advancements in Retrieval Augmented Generation: Addressing RAG's Challenges with CAG & KAG
Natural Language Generation (NLG) has made great strides in recent years in enabling machines to produce human-like texts, respond to queries, and even engage in meaningful conversations. LLMs generate texts based on the knowledge they have been initially trained on. Retrieval-Augmented Generation (RAG) helps to marry pre-trained language models with external enterprise information, which may not be available within the LLMs. RAG has been key in embedding accurate factual content and providing fast and contextually relevant responses, making it a cornerstone in applications like chatbots, document summarization, and question-answering.
Nonetheless, with the increasing adoption for AI-driven systems there has been an increase in awareness of the limitations of RAG. The high latency, reliance on external retrieval systems, and inability to cater to dynamic or context-sensitive queries have ushered in the need for a more powerful and efficient solution.
The newer approaches, such as Cache-Augmented Generation (CAG) and Knowledge-Augmented Generation (KAG), are expected to fill some of the gaps of RAG with innovative mechanisms to aid both speed, efficiency as well as contextuality.
Challenges with Retrieval Augmented Generation (RAG)
While RAG has revolutionized the use of external knowledge in language models, it is not without its drawbacks.

These challenges underscore the need for more efficient and reliable methodologies, paving the way for Cache-Augmented Generation and Knowledge-Augmented Generation.
The Promise of Cache-Augmented Generation (CAG)
How CAG Works
Cache-Augmented Generation (CAG) provides a local memory-based caching function that saves and reuses frequently accessed data or context. CAG becomes efficient and fast by caching the most needed information. It enables avoiding repeated external retrievals.
For example, in a customer support chatbot, CAG could use local caching to store frequent queries and their corresponding answers. When a user poses a recognizable question, the system returns the cached answer instead of querying external knowledge stores, thereby substantially reducing latency.
How CAG enhances the capabilities of RAG
CAG doesn’t replace RAG rather supplements the capabilities of RAG by providing the below listed features:
- Enhanced Speed and Reduced Latency
The CAG fetches cached data and avoids blocking calls to external, resource-heavy retrieval systems. Hence, it fits an application model requiring near real-time responses. - Improved Efficiency for Redundant Queries
The CAG is justified in scenarios where the same answer is required for repeated queries. To conserve resources, alternatively, the cached data will be used rather than repeatedly fetching the same data from the database. - Restricted Environment Compatibility
The CAG’s local storage functionality helps in ensuring seamless operation in environments with challenging internet connectivity.
Differentiation Between RAG and CAG
| Aspect | RAG | CAG |
|---|---|---|
| Retrieval Process | Relies on external systems. | Uses locally cached data. |
| Latency | Introduces delays due to external calls. | Minimizes latency with local retrieval. |
| Scalability | Computationally intensive. | Efficient for repetitive queries. |
| Use Cases | Suitable for dynamic knowledge updates. | Ideal for static or predictable queries. |
Example Scenarios for CAG
- Customer Support Mechanisms
E-commerce service customers repeatedly ask questions on topics such as return policy and order status. Therefore, the CAG-enabled chatbot helps maintain the local cache memory of the responses, which would allow instant presentation within the same conversation without needing to consult the external database.2. Personalized Financial Advice - Personalized Financial Advice
Cache common index fund info (performance, risk factors, analyst ratings) for quick, personalized responses to repeat queries. This saves the bot from recalculating metrics each time
The Evolution to Knowledge-Augmented Generation (KAG)
How KAG Works
Knowledge-augmented generation (KAG) is dissociated from the traditional framework by embedding domain knowledge directly into the architecture or training of the model. However, it is not similar to the finetuning model with domain data rather it pre-loads with encyclopedia of domain-specific knowledge. This knowledge structure provides a rich context for the model using ontologies, knowledge graphs, and pre-trained datasets.
When one asks a KAG-powered bot about any specific topic, it doesn't just look up for that topic only; rather, it understands how that topic connects to other areas in its encyclopedia to extract information around it.
This will help in suggesting accurate context-based recommendations in an example where such systems in KAG may be combined with medical ontologies through diagnosis, based on symptoms presented by a patient.
Advantages of KAG
- Deeper Context Awareness and Reasoning
KAG can build its understanding through complex, multi-part questions, while RAG is better at just gathering individual pieces of information. - Reduced Dependency on External Sources
By adding knowledge directly inside the model, KAG minimizes the chances of retrieving irrelevant or outdated information from external sources. - Domain-Specific Expertise
KAG is more efficient in specialized areas such as health care, finance, and legal services, where domain expertise is an underlying factor.
Differentiation Between KAG and RAG
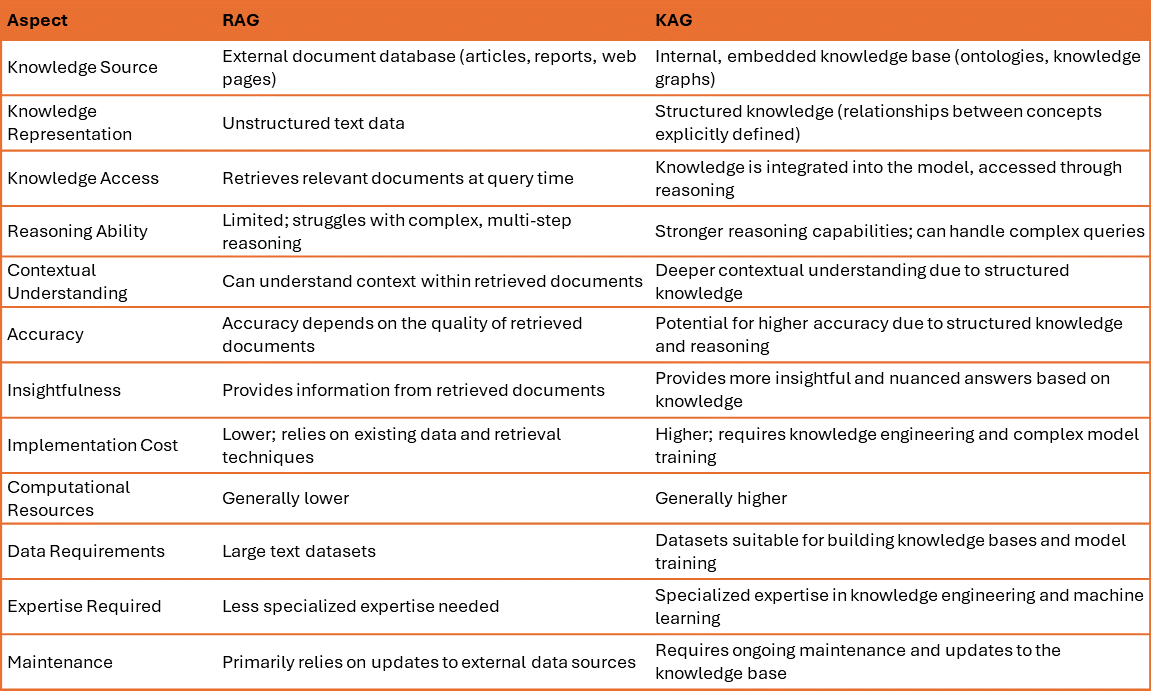
Example Scenarios for KAG
- Healthcare Diagnostics
A KAG-based platform can perform an analysis of patient symptoms and medical histories by integrating knowledge obtained from medical ontologies to suggest possible diagnoses or treatment options. - Financial Analysis
In the financial sector, KAG can provide detailed market insights or risk analyses by reasoning over structured data against historical trends.
Not Distinct Architectures, but a Unified Evolution
RAG, CAG, and KAG should be viewed as a continuous evolution of knowledge-based architectures, not as distinct, competing approaches. A typical design process would begin with RAG, then incorporate CAG for caching, and finally integrate KAG for specialized domain queries
A Unified Example: Customer Support in a Tech Company
- RAG: Handle requests that require real-time information on product updates, such as announcing new features.
- CAG: Handle frequently asked questions on troubleshooting steps for common problems.
- KAG: Answers difficult inquiries that require reasoning, such as understanding compatibility among products.
Conclusion
Emergence of Cache-Augmented Generation and Knowledge-Augmented Generation represents a huge advancement in the AI model's journey. These approaches promise swift and accurate results that are contextually aware by working toward the limits posed by Retrieval-Augmented Generation. By addressing the limitations of Retrieval-Augmented Generation (RAG), these methodologies promise to deliver faster, more accurate, and contextually aware responses.
At Coforge, we are committed to staying at the forefront of this innovation, exploring, experimenting, and integrating these technologies into our solutions. It is an exciting time to be in the AI landscape, and we are thrilled to ride this wave.
Visit Coforge Quasar to learn more about our innovations in AI.

Susmit Sil is a forward-thinking Enterprise Architect, AI CoE, Coforge Technologies. He has 20+ years of IT experience with strong technology leadership experience in Emerging Technologies i.e. Generative AI, Deep Learning, NLP, Speech, Conversational AI, Responsible AI, Blockchain.
Related reads.



About Coforge.
We are a global digital services and solutions provider, who leverage emerging technologies and deep domain expertise to deliver real-world business impact for our clients. A focus on very select industries, a detailed understanding of the underlying processes of those industries, and partnerships with leading platforms provide us with a distinct perspective. We lead with our product engineering approach and leverage Cloud, Data, Integration, and Automation technologies to transform client businesses into intelligent, high-growth enterprises. Our proprietary platforms power critical business processes across our core verticals. We are located in 23 countries with 30 delivery centers across nine countries.